How to Use BISAC Codes to Increase Your Book's Visibility on Amazon

Metadata in publishing is the information about a book: it includes the author, title, description, keywords, and BISAC codes.
Ebook metadata input is important for your book distribution and a powerful tool for promotion and sales.
PublishDrive has teamed up with a publishing metadata expert, Zsofia Dedinszky, who has kindly agreed to share her extensive knowledge with us.
In this article, I go over what BISAC is and the best practices for selecting the correct BISAC codes and placing the book in the right category on Amazon.
Key Takeaways
- Metadata, including BISAC codes, is vital for book distribution and sales. BISAC codes categorize books, helping retailers and buyers find them easily online and offline.
- Choose accurate and specific BISAC codes that represent your book's content. Focus on detailed subcategories to enhance visibility and ensure proper classification.
- Understand the difference between standard BISAC codes and Amazon categories. Use keywords strategically and select categories carefully on Amazon to optimize book visibility and increase chances of achieving bestseller status.
What Is a BISAC Code?
BISAC codes are part of your book’s metadata. A BISAC code tells retailers, libraries, sellers, buyers, and search engines what genre your book falls into.
In short, it’s a way to categorize your book.
BISAC is currently the most widely accepted classification system by most distributors, including Amazon (although BISAC codes on Amazon are a bit different, we’ll see this later).
The BISAC system was developed by the Book Industry Study Group and is updated yearly. The BISAC Subject Headings List categorizes titles with book industry standards and communications. The current BISAC Subject codes are available to anyone for free. They also have a helpful FAQ on selecting the right category for a book.
With PublishDrive’s Book Metadata Generator (part of the Publishing Assistant), you can create optimized metadata in minutes. The tool tackles the technical aspects for you, generating essential components like keywords, BISAC categories, Amazon categories, and even blurb ideas. It helps your book get discovered faster by the right readers, all without replacing your creative input.
The Importance of BISAC Categories
The classification system decides where your book should be in stores.
Everybody understands the importance of knowing where to look for a book in a brick-and-mortar store. You either immediately go to the cookbooks in the basement or to the language books on the third floor: a misplaced book has a smaller chance of being found.
It is exactly the same for ebooks on Amazon or any other online store.
Unless somebody knows what they are looking for and is searching for your name or title, they’ll browse through a category that interests them.
A badly classified book disappoints readers. If somebody expects to read a paranormal shifter romance but gets a psychological thriller instead, they are understandably unhappy. They might leave a negative review on your otherwise fantastic book.
Selecting the Right BISAC Codes for Your Ebook
How should you pick the best BISAC code?
You need only one code when you upload your book on Amazon KDP. But, since your book is not just about one thing, you can select up to three BISAC categories and appeal to more people.
However, the first code is the primary one and should be the most accurate.
All classification systems work with a relatively small number of broad genres, e.g., fiction and nonfiction. The broad genres are then divided into sub-genres (Fiction / Christian), then into even smaller genres (Fiction / Christian / Futuristic), or even smaller (Fiction / Mystery & Detective / Cozy / Crafts).
1. Check the BISAC codes list
Go to the BISAC Subject Headings and search for the most accurate category your book belongs to.
You’ll find there are many categories arranged alphabetically.

2. Select your book’s subcategories
Once you find your primary BISAC category, select the relevant subcategories.
After you pick your code from the BISAC classification, you’ll have a broad range of subcategories and their BISAC codes.

Repeat two more times.
🔥 Here is what you should know in a nutshell.
👉 Choose appropriate categories
For years, authors have inaccurately categorized their books, aiming for better rankings in less competitive categories. This strategy won't benefit you over time. Ensure you select only categories that genuinely match your book's content. If not, Amazon may either remove your book from these categories or assign it to categories you didn't intend to be in.
👉 Focus on specific subcategories
When specifying your book's categories, choose the most detailed subcategories possible. These subcategories typically face less competition and help Amazon understand your book's theme more accurately. Additionally, selecting a subcategory groups your book into the broader categories above it, enhancing visibility.
👉 Explore creative options
Even if your book fits best in a highly competitive category, consider also identifying niche categories where it could also align.
9 Tips to Follow When Selecting BISAC Categories
1. Pick a category for the entire book
You should always pick your book’s main BISAC category that applies to the entire book, not just a few chapters.
2. Don’t use a category and its subcategory
For example, don’t pick both Fiction / African American and Fiction / African American / Mystery & Detective. The latter already includes the former.
3. Be as specific as you can
Spend time getting to know the list and discovering your options. Selecting Fiction / General is not such a good idea as the topic is… general.
For example, if your book is literary fiction, select Fiction / Literary.
4. Be honest
If your book is not suitable for kids, don’t classify it as such. If your book is for kids, select the appropriate target audience.
5. Don’t use non-fiction categories for a fiction book
For example, if you wrote a novel that mentions poker a lot, don’t classify it as Games & Activities / Card Games / Poker. It’s still fiction.
Fiction books should only go under FIC, JUV (kids’ fiction), or YAF (YA fiction) categories.
6. Go for the one with the least competition
Amazon is a competitive place. If you want to help your book get on the bestseller list, you should pick a less competitive category (if possible). Check your categories of choice on Amazon to see the total number of books in that category.
7. Be creative
If your book is cross-genre, pick more BISAC categories and codes. You can do this better for non-fiction books.
For example, a book about the positive effects of decluttering can go under Home & Garden, but also under Self-Help. Similarly, a business book can go into Business, Self-Help, and even into Biography if it’s based on your life story.
8. Be consistent with your BISAC codes
If you distribute your book in more than one format, use the same BISAC codes for all of them.
This means the BISAC code for your print book should be the same as for your ebook and audiobook.
9. Reevaluate your choice every now and again
BISAC codes are updated yearly. Check the list of available categories regularly and be ready to re-categorize your book if something more suitable comes up.
Enter the BISAC Codes in PublishDrive
PublishDrive uses BISAC for categorization and lets you select three categories. All of our partner stores accept the BISAC codes we send and use them to determine the correct category for your book in their system (if they are not using BISAC).
While most retailers will use all three BISAC subject codes you selected, the primary subject is the most important.
Check out our support article on how to upload your book in PublishDrive. It has all the necessary information, including how to select your BISAC codes.
Difference Between BISAC Codes and Amazon Categories
BISAC codes help the publishing industry classify content. However, the genres are not very specific.
This may place your book into a broader category.
Amazon’s categories, on the other hand, help you place a book into a more specific genre.
Amazon also has BISAC codes, but they are a bit different than the standard ones we discussed.
Standard BISAC categories and Amazon categories are two separate things. But keep in mind that standard BISAC codes allow Amazon to place your book in the proper category when you send your book through an aggregator. Also, they both work to increase your book’s visibility.
Selecting the best Amazon category
Getting into the right category is always important, but it has special importance at Amazon.
Amazon bestseller ranks are calculated per category, and it is easier to achieve a higher rank if the competition is not that fierce.
Amazon calculates a book's Amazon Best Seller Rank (ABSR) by comparing its sales or downloads over a certain time frame with all other books available on Amazon.
To begin, enter keywords related to your book in the Amazon search bar to generate a list of similar titles.
Below are details for Salman Rushdie’s Victory City.
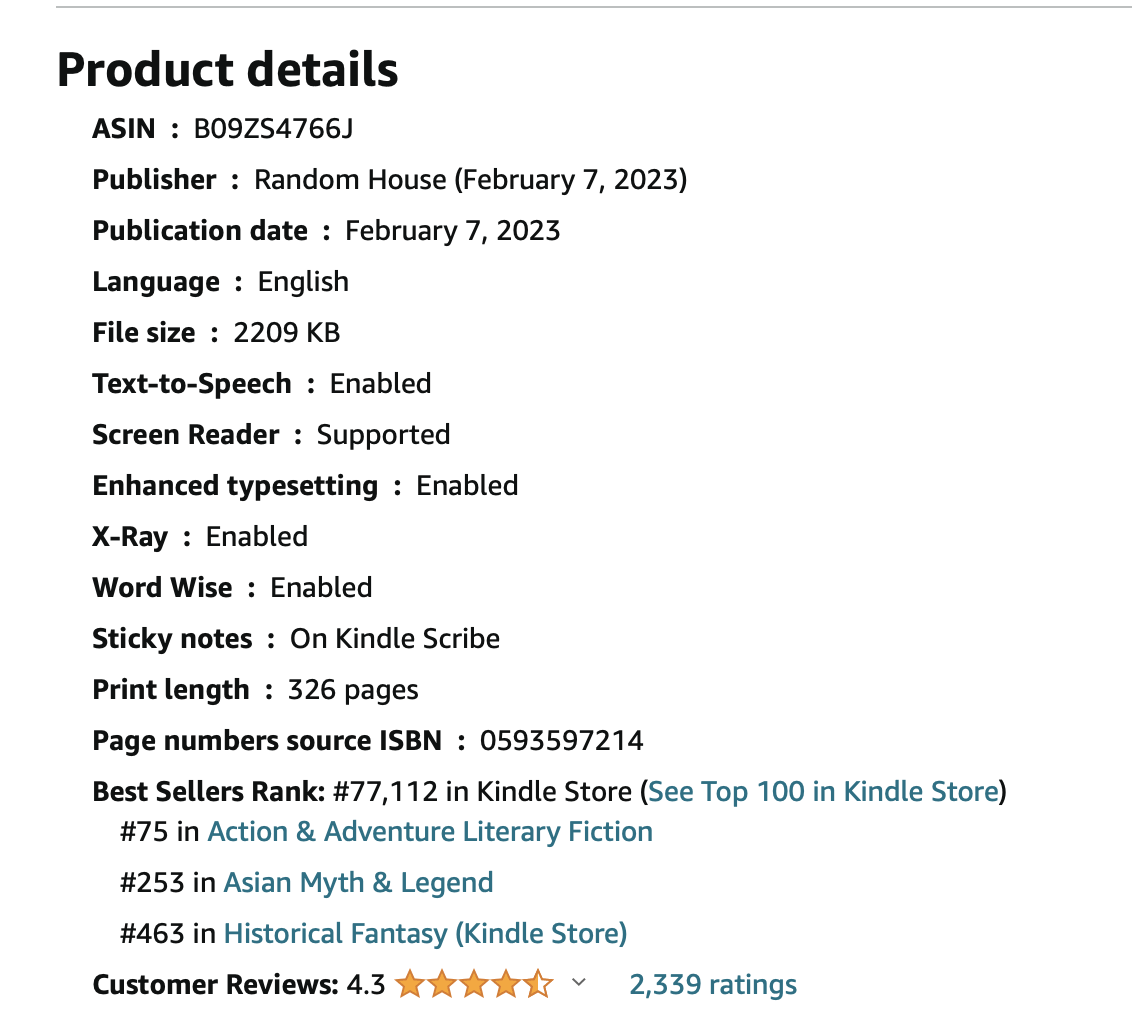
Alternatively, you can navigate through Amazon's categories via the sidebar until you identify the specific categories suitable for your book.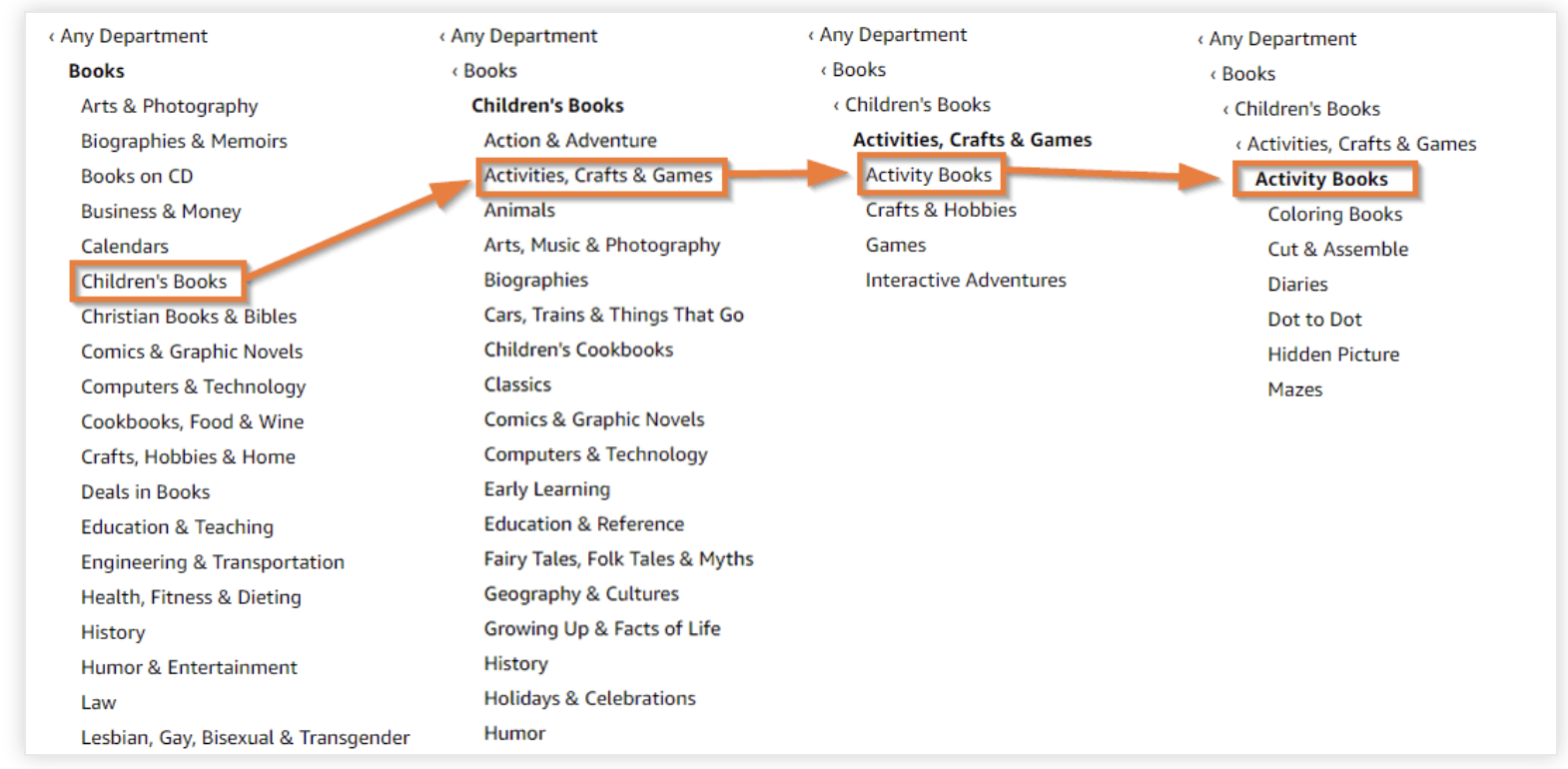
With a list of potential categories in hand, the next step is to determine which one offers the best opportunity for achieving and maintaining bestseller status. Click on a book's category link on its sales page to view the Bestsellers in that category.
Then, select the #1 bestselling book in your chosen category and note its ABSR found on the sales page. This is the target ABSR you must surpass to become the #1 bestseller in that category.
After compiling a list of categories along with the ABSR of their top-selling books, use the Kindle Calculator to estimate the number of sales needed today to reach the top bestseller spot in those categories.
Finally, review your list and select categories that accurately reflect your book's content and have the most attainable ABSR targets.
Selecting via an aggregator
But how to get into the right category on Amazon, especially if you are not going through KDP but an aggregator?
Amazon’s category list doesn’t completely match any industry standard categorization.
Even the Amazon subcategories differ per domain: you’ll find a different selection on Amazon.com than on Amazon.co.uk, just as all the language-specific subdomains.
If you go through an aggregator like PublishDrive, you are covered. PublishDrive has a mapping between BISAC and Amazon's category list. This means the platform recognizes which BISAC item corresponds to each Amazon category item and automatically places your book in the right category.
Since Amazon’s inventory is too large for consumers to browse through a general topic section, they search using keywords.
This means you can include a few keywords in your book’s metadata that target readers’ intent and increase your book’s discoverability.
To Sum It Up
The BISAC system is important if you want to set your book to success. Once you understand what BISAC codes are and which ones you need, pick three of them together with their categories.
When you apply these BISAC categories on Amazon, your books will get properly distributed in the platform's book groups whenever you send them through an aggregator.
Ready to self-publish your book?
It’s free to publish your 1st ebook on PublishDrive. Or try out a paid plan and get your money back if you’re not satisfied.